 统计学是一门应用很广泛的学课,也是AP报考的热门科目,然而统计学也不是那么好对付的,很多人甚至觉得它比微积分还要难。今天我们邀请了来自「创作计划」的Anna同学,为我们带来超详细的AP统计备考攻略。
一篇文章告诉你:什么时间开始学,需要准备的书籍、工具以及学习中一些非常重要的知识点,相信定会为你的备考带来帮助。
统计学是一门应用很广泛的学课,除了统计学本身外,很多其他的专业,例如经济,社科,甚至生物化学都需要用到统计学的知识。然而统计学也不是那么好对付的,很多人甚至觉得它比微积分还要难(而且从五分率来说确实如此)。
笔者是在高二时期学习的统计学,在此之前有一定的微积分基础(意思就是我高一拿了微积分5分)。然而统计学学得不是很轻松。在很长一段时间我的选择题正确率只能保持在百分之75左右,差不多刚刚符合5分的正确率。
而错题的理由是多种多样的,即使笔者觉得自己很擅长计算。不过在几次模考之后,我总结了一下自己的错误,然后慢慢改正了一些自己理解错误的地方。在这里笔者分析一些统计考试需要知道的东西以及一些重要的知识点。
统计学是一门应用很广泛的学课,也是AP报考的热门科目,然而统计学也不是那么好对付的,很多人甚至觉得它比微积分还要难。今天我们邀请了来自「创作计划」的Anna同学,为我们带来超详细的AP统计备考攻略。
一篇文章告诉你:什么时间开始学,需要准备的书籍、工具以及学习中一些非常重要的知识点,相信定会为你的备考带来帮助。
统计学是一门应用很广泛的学课,除了统计学本身外,很多其他的专业,例如经济,社科,甚至生物化学都需要用到统计学的知识。然而统计学也不是那么好对付的,很多人甚至觉得它比微积分还要难(而且从五分率来说确实如此)。
笔者是在高二时期学习的统计学,在此之前有一定的微积分基础(意思就是我高一拿了微积分5分)。然而统计学学得不是很轻松。在很长一段时间我的选择题正确率只能保持在百分之75左右,差不多刚刚符合5分的正确率。
而错题的理由是多种多样的,即使笔者觉得自己很擅长计算。不过在几次模考之后,我总结了一下自己的错误,然后慢慢改正了一些自己理解错误的地方。在这里笔者分析一些统计考试需要知道的东西以及一些重要的知识点。
什么时候学
值得注意的是,学习统计学,是需要花费很多时间的。统计学既有数学传统的需要理解消化并应用的部分,也有许多需要记忆的点。对于数学天赋较好的同学,在准备AP微积分的时候由于他们很容易理解其中的知识,所以不需要很多时间来应试AP微积分—但他们仍然需要花很多时间来准备AP统计学。 此外,最好不要把AP统计学和AP微积分放在同一阶段准备。不仅仅是会让考生受到过大的数学方面的压力,同时由于AP微积分和AP统计学会采用两种不同的思考方式,学习起来会相当困难,效率也不是很理想(当然如果是标化,数学dalao还是可以尝试一下的)以一般理科或工科为专业的同学可以考虑高一微积分高二统计,或是高二微积分高三统计。如果是统计为核心的专业也可以选择先准备统计。
 一边更注重于代数的变形,计算,一边更注重于案例的解析,同时学微积分和统计真的十分痛苦。
一边更注重于代数的变形,计算,一边更注重于案例的解析,同时学微积分和统计真的十分痛苦。
开始学习的准备
除了一般的巴朗,普林斯顿这些应试用的材料。课本上笔者推荐W H Freeman and Company编的The Practice of Statistics。 这本书的结构很清晰,有很多对考试很有帮助的细节,并且还内含许多题目(真的很多)。推荐大家用这本书学习然后刷刷巴朗的模考或是往年真题。
PS: 笔者选择的巴朗。巴朗许多课后习题真的不怎么样。
另外,由于AP统计支持计算器,同学们也需要准备一个。计算器的应用在这个考试里真的很重要,有些题目直接用计算器做会省去很多的时间。举个例子:算binomial的时候,你可以辛辛苦苦把数字带进公式再按计算器,或是直接计算器里按Distribution→Binominal→Bpd/Bcd就可以了
由于高中SATⅡ老师的推荐,笔者一直在用CASIO的fx-CG10计算器。这个计算器足以应对几乎所有ap统计学的知识点了。
统计学考试还会提供公式表,但并不是很全面:有些还是需要背的。
这本书的结构很清晰,有很多对考试很有帮助的细节,并且还内含许多题目(真的很多)。推荐大家用这本书学习然后刷刷巴朗的模考或是往年真题。
PS: 笔者选择的巴朗。巴朗许多课后习题真的不怎么样。
另外,由于AP统计支持计算器,同学们也需要准备一个。计算器的应用在这个考试里真的很重要,有些题目直接用计算器做会省去很多的时间。举个例子:算binomial的时候,你可以辛辛苦苦把数字带进公式再按计算器,或是直接计算器里按Distribution→Binominal→Bpd/Bcd就可以了
由于高中SATⅡ老师的推荐,笔者一直在用CASIO的fx-CG10计算器。这个计算器足以应对几乎所有ap统计学的知识点了。
统计学考试还会提供公式表,但并不是很全面:有些还是需要背的。
统计学一些重要的点
Sampling Distribution
按照学习顺序的话,这部分应该是最后一大节。同时也结合了前面几乎所有的知识。这部分也是考试中计算部分中最多的一项。自然,我们先从最难的讲起。 1) 概要 Sampling不是sample,是许多个sample size 相同的sample组成的一种统计方法。在选择题中可能会遇到类似的纠错题目。此外,一些名词的概念一定要分清楚:statistics or parameter. Sampling Distribution 有许多不同的应用:Confidence Test, Significance Test, Comparing, Chi-Square Test,sampling distribution of slope。这些应用有着相同的解题方法(state plan do conclude),有些公式也可以互通(standard error)。 2) 方法 对于investigative 题目,无论如何,都要牢记 state plan do conclude。 State:命名一些terms 的含义:p代表哪一个的概率?H0是什么null hypothesis? Plan:检查condition. Do:喜闻乐见的计算 Conclude:得出结论 Ps:其实这种方法对于所有statistics problem都通用。这部分恰好用得最多而已。 此外,大部分test都有proportion和mean的区别,而这两个采用的公式是不同的!核对的图表,甚至名字也不一样(significance test中,proportion叫做z-test,而mean是t-test)。 3) 条件 这部分会涉及到的前置条件有: Random: 一般需要证明10% condition:n≤1/10 N(他也是需要standard deviation计算的条件) Large Counts : Proportion 需要的条件:np 和 n(1-p)需要至少是10. Large Sample: mean 需要的条件 sample size大于等于30时,无论population如何都可以满足normal的条件。如果不确定的话,同学们就需要自己作图来证明normal了。 Chi-Square Test的Large counts:expected counts大于等于5 核对条件是做investigative test 一个非常重要的部分,在分值上也占着很大的比例。从逻辑上来说,连条件都满足不了是没有办法来计算的。所以这部分一定要认真应对。 4) 计算 这部分就是考验大家对公式的熟悉程度了。学习统计的同学们也早已把这些公式背得滚瓜烂熟了吧。只是有些常见错误,大家也有可能会遇到。 核对图表:confidence部分的critical value,significance中的p-value,在proportion和mean的是不一样的。还有就是找数字的时候不要看错行了。 不同test的degrees of freedom计算方法不同confidence 和 significance是n-1,chi-square则是行列个数各减1的积。 Standard error 和 standard deviation。大部分时候大家都需要算一下error的。但值得注意的是:有些时候题目会提供表格,格式是这样: 这里的SE Coef就是error了,算的话直接取数字,没必要再除一个根号n了。
Power, α,β的区别。α是type 1 error, β是type 2 error,power是1-β。变化趋势上,α越大,β越小,power越大。
分清chi-square test中的homogeneity 和 independence。区别在于sample是1-sample还是2-sample上。选择题可能比较多。
H0/Null hypothesis 一定要是一个等号。通过这点也可以判断文字H0中选择是该写different 还是 not different,是independent 还是 not independent.
计算最后:写conclusion.
这里的SE Coef就是error了,算的话直接取数字,没必要再除一个根号n了。
Power, α,β的区别。α是type 1 error, β是type 2 error,power是1-β。变化趋势上,α越大,β越小,power越大。
分清chi-square test中的homogeneity 和 independence。区别在于sample是1-sample还是2-sample上。选择题可能比较多。
H0/Null hypothesis 一定要是一个等号。通过这点也可以判断文字H0中选择是该写different 还是 not different,是independent 还是 not independent.
计算最后:写conclusion.
Binominal 和 Geometry
在5个中有多少概率会抽到至少3个success?抽出7个后出现一次success的概率是多少?这些就是最基本的binominal和geometry distribution的例子。 基本上都是算概率或者其中的mean,standard deviation。这种distribution也有自己的condition/setting,在遇到的时候也要去检查这些。可以概括为: Binominal中BINS:binary,independent,number,success. Geometry中BITS:binary,independent,trials,success. 此外:binominal中对mean 和 standard deviation中的算法是sampling和其各种test的证明基础,学好前者对理解后者是有帮助的。Probability
学统计学的同学们对p(x)这种符号肯定不陌生。在部分中,同学们将会遇到一些定义以及probability特有的计算方式。除此之外:probability的主要点在于交集并集的运用, conditional probability了,以及mutually exclusive和independent 概念了。 P(A∪B) = P(A) + P(B) - P(A∩B) Mutually exclusive → P(A∩B)= 0 这里需要注意的交集(∩)和并集(∪)符号的问题:前者是and,后者是or。在conditional probability的情况下。采用tree diagram会对做题很有帮助。图像/Mean and Standard Deviation
Ap统计学涉及到了许多不同的图像:histogram,boxplot,scatterplot。解析图像时一定要谈到shape center spread 三个方面。 Normal 是最重要的shape,算出z-score后每一块的占比都能轻松算出来。Right-skewed , left-skewed 以及含有多个峰值是一个不是normal的图像可能有的特点。而right-skewed left-skewed也可以推倒mean 和 median哪一个是较大的那一个。 Box plot 有5 number summary的部分:min Q1 median Q3 max。推倒IQR是判断outlier的核心。 Mean,standard deviation算是ap statistics 出场率超高的两个量了吧。他们的公式想必也不需要细说了。不过值得注意的是在不同情况下这两个量会采用不同的公式。注意分清就可以回避大部分错误了。Experiment 有关的定义
Observational study,experiment有什么区别,under coverage是什么,这些定义只要分清楚是不难的。选择题中会给出实例然后让考生进行判断:这些题目只需要多加练习就可以熟练地进行判断。 但是strata和 cluster的区别可能容易搞混。同样是归类,strata是把同时具有某种特征的individuals归为strata,而cluster只是把相邻的individuals归为cluster。之后遇到的block和strata类似。最后…
最后,同学们一定要注意的是:在回答统计学问题时一定要做到尽善尽美,不能放过每一处细节点。这里举一个例子: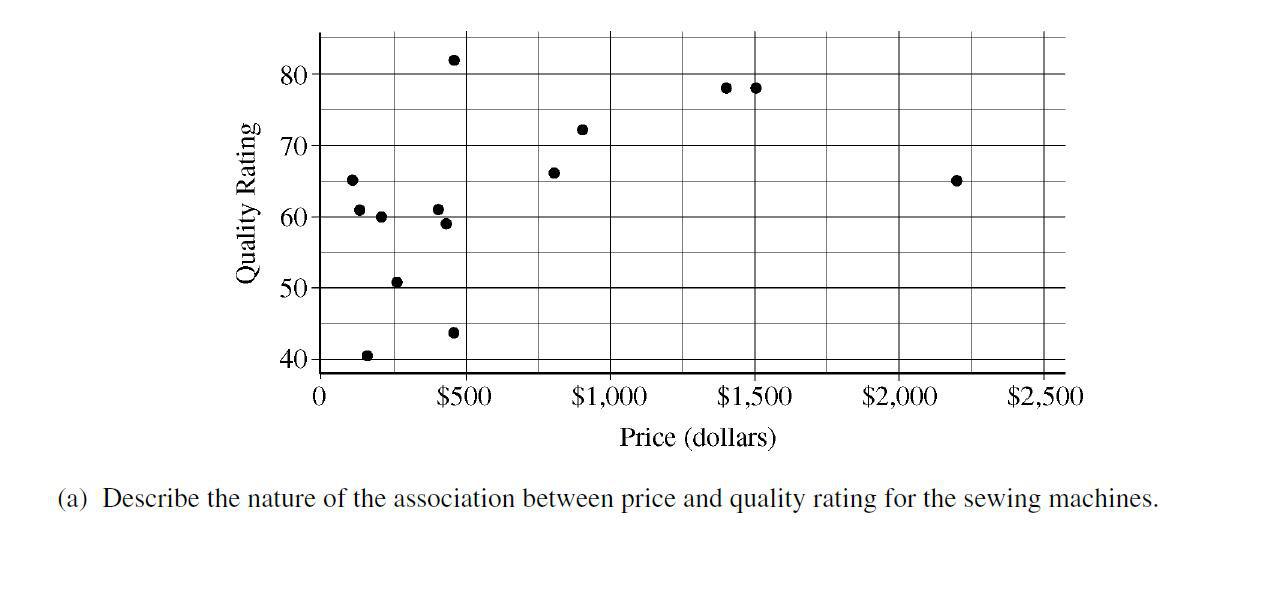 大意就是描述scatterplot 中两个variable的关系。看起来是一道很直白的题目,又是free response的第一题。的确,通过阅读图像就可以完成的题目确实很直白,但是经常有同学因为写得不够完善而扣分。这道题需要涉及到的点有:
1) Weak and positive association
2) Not very linear
3) Points with price less than 500 do not have clear association
4) Points with price more than 500 generally have greater quality rating, making the overall association positive。
回答的越全面,就能拿到越高的分。通过练习,同学们都可以熟悉ap统计学的这种思维方式。
相信大家在不断锻炼后都可以取得满意的分数!
大意就是描述scatterplot 中两个variable的关系。看起来是一道很直白的题目,又是free response的第一题。的确,通过阅读图像就可以完成的题目确实很直白,但是经常有同学因为写得不够完善而扣分。这道题需要涉及到的点有:
1) Weak and positive association
2) Not very linear
3) Points with price less than 500 do not have clear association
4) Points with price more than 500 generally have greater quality rating, making the overall association positive。
回答的越全面,就能拿到越高的分。通过练习,同学们都可以熟悉ap统计学的这种思维方式。
相信大家在不断锻炼后都可以取得满意的分数!
AP各科选择题真题打包下载福利(超过10科)
请扫码添加TD客服微信
并发送关键字「AP真题」领取~







